Foundry Toolkit for Visual Studio Code
Foundry Toolkit for Visual Studio Code helps developers and AI engineers build, test, and deploy AI apps with generative AI models. You can use it locally or in the cloud to manage your full AI app workflow in one place.
Foundry Toolkit offers seamless integration with popular AI models from providers like OpenAI, Anthropic, Google, and GitHub, while also supporting local models through ONNX and Ollama. From model discovery and experimentation to prompt engineering and deployment, Foundry Toolkit streamlines your AI development workflow within VS Code.
Key features
| Feature | Description | Screenshot |
|---|---|---|
| Create agents | Use different techniques to create Prompt Agents utilizing tools and vectors or Hosted Agents with custom code. | 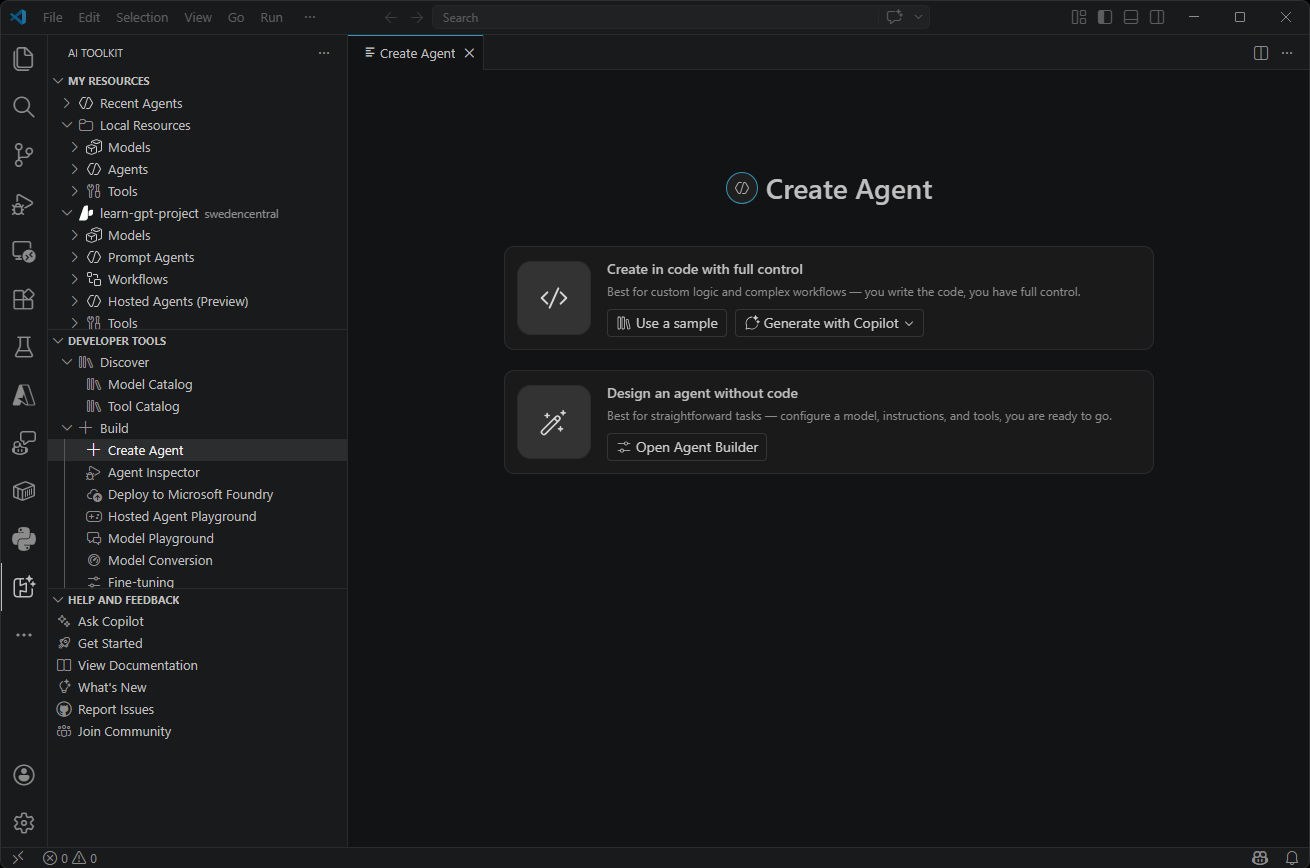 |
| Model Catalog | Discover and access AI models from multiple sources including Microsoft Foundry, Foundry Local, GitHub, ONNX, Ollama, OpenAI, Anthropic, and Google. Compare models side-by-side and find the perfect fit for your use case. | 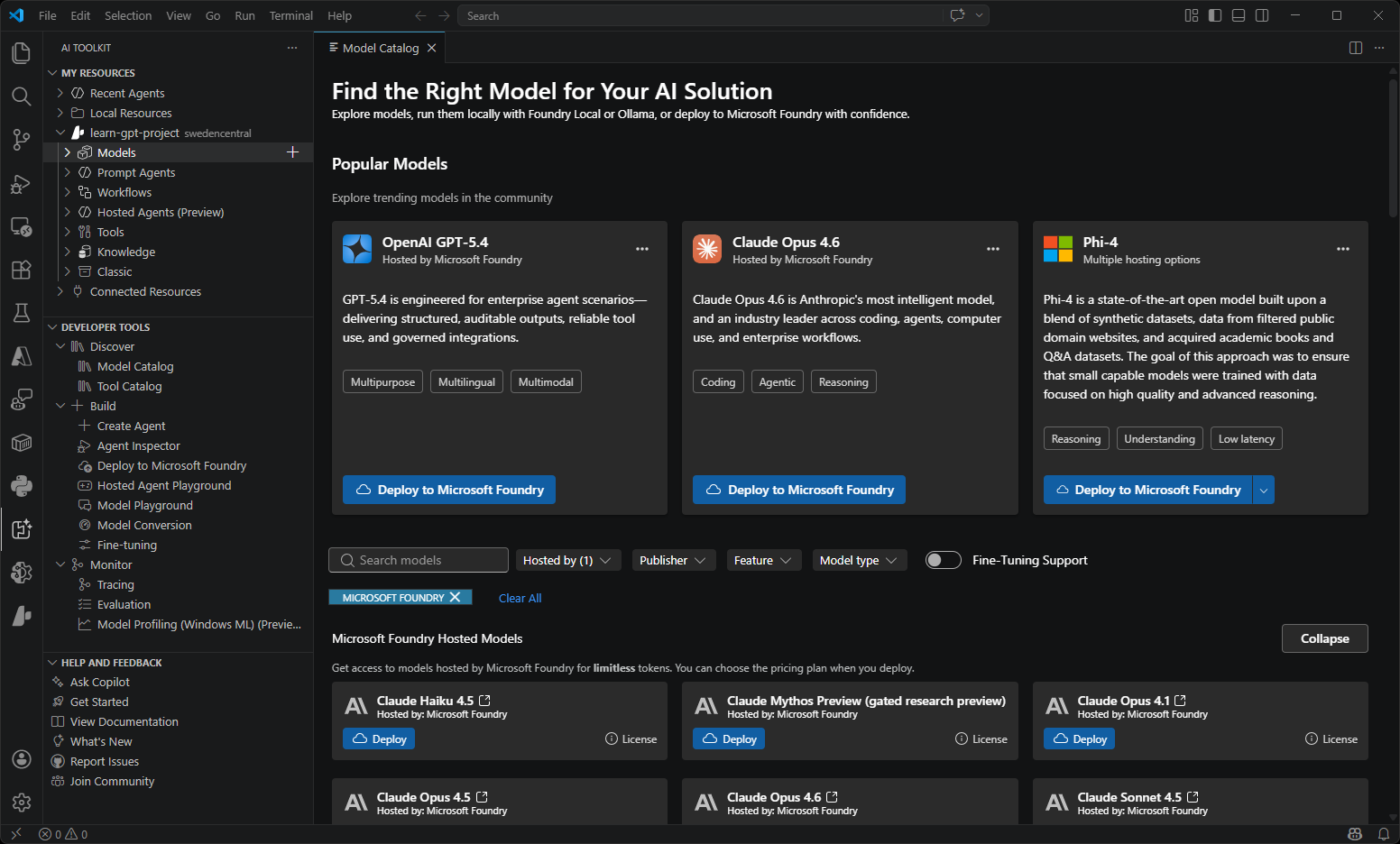 |
| Playground | Interactive chat environment for real-time model testing. Experiment with different prompts, parameters, and multi-modal inputs including images and attachments. | 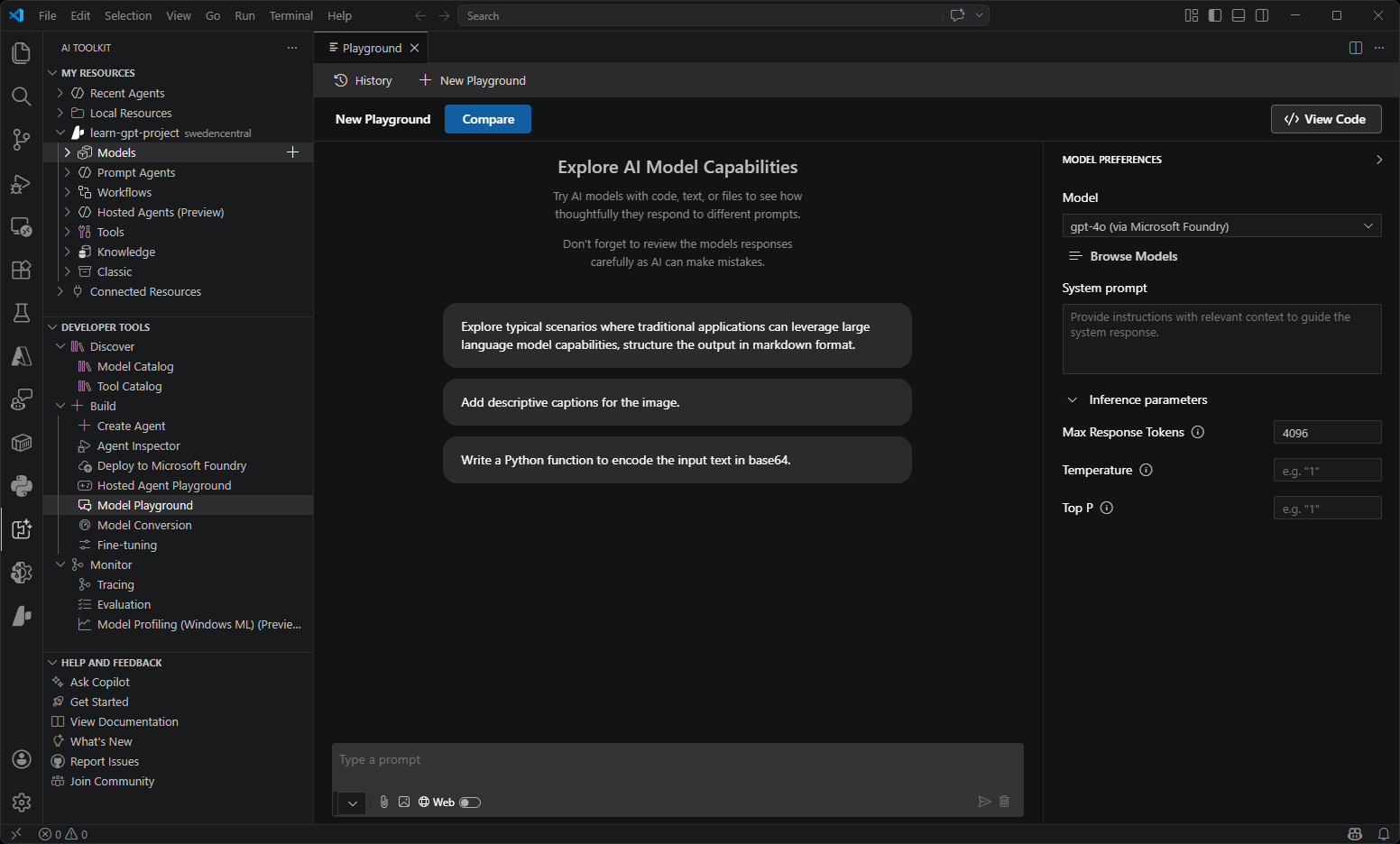 |
| Agent Builder | Streamlined prompt engineering and agent development workflow. Create sophisticated prompts, integrate MCP tools, and generate production-ready code with structured outputs. | 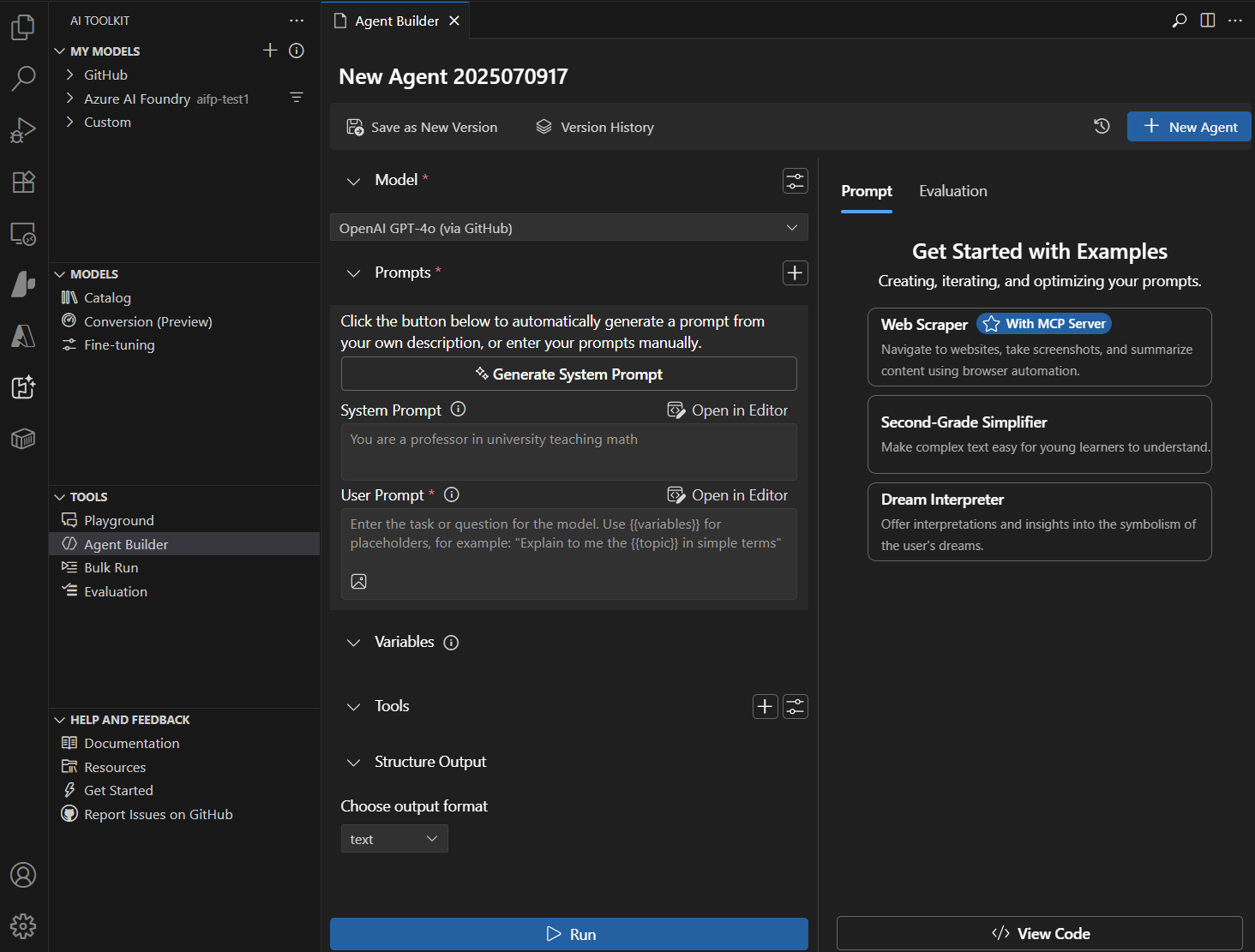 |
| Agent Inspector | Debug, visualize, and iterate on AI agents directly within VS Code. | 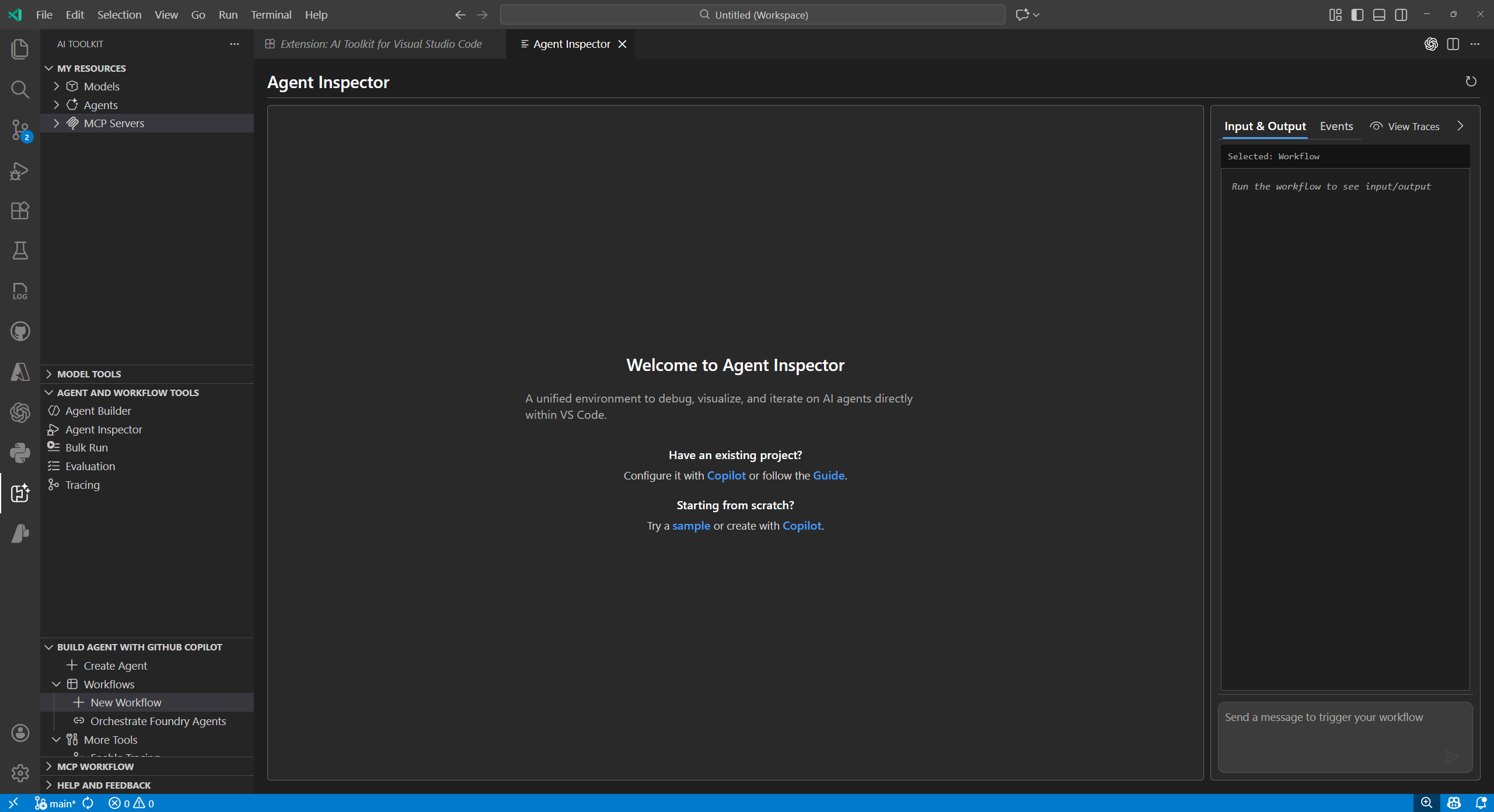 |
| Model Evaluation | Comprehensive model assessment using datasets and standard metrics. Measure performance with built-in evaluators (F1 score, relevance, similarity, coherence) or create custom evaluation criteria. | 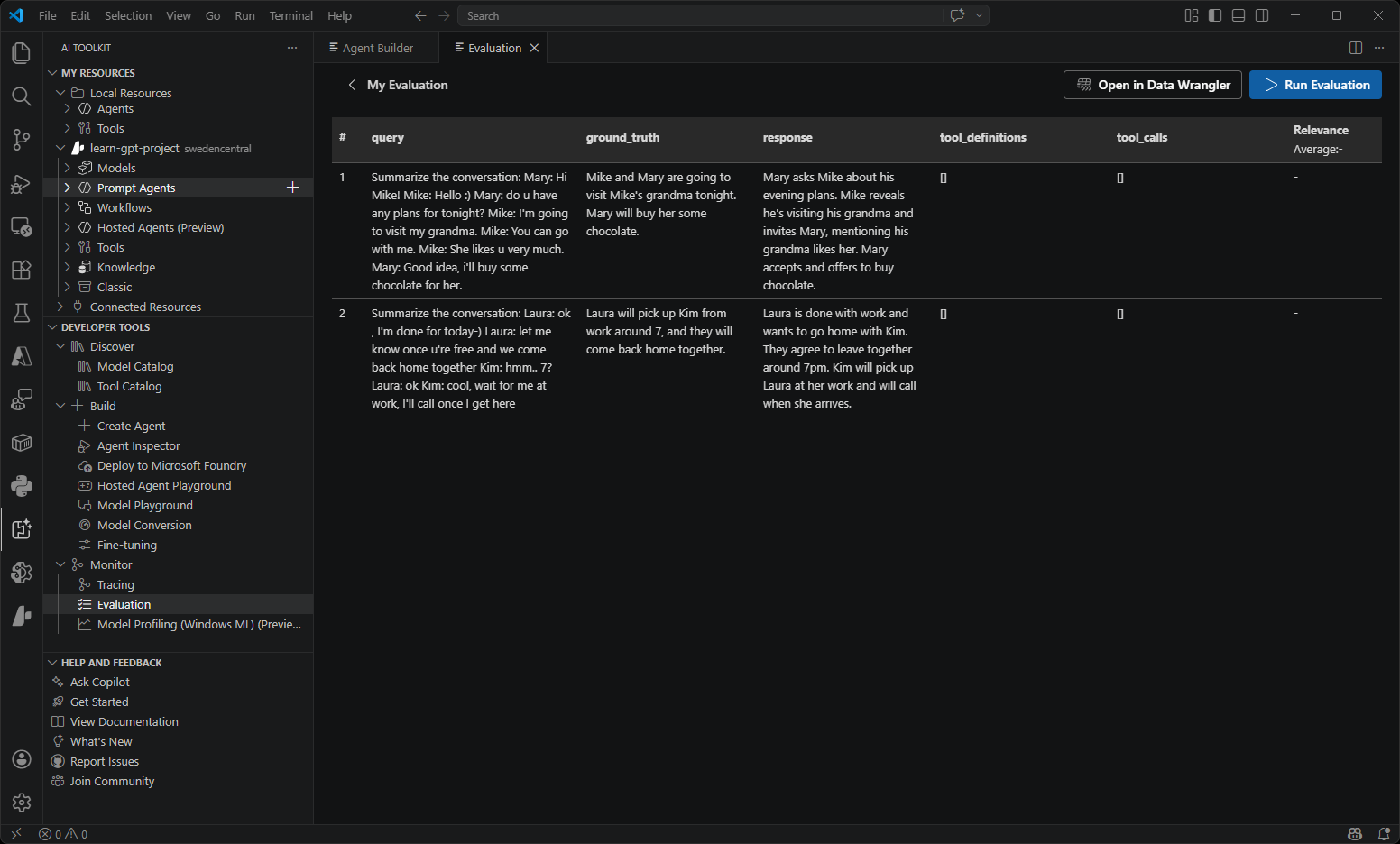 |
| Tool Catalog | Connect Foundry tools and local MCP server tools using the Tool Catalog in Visual Studio Code and add them to agents with Agent Builder | 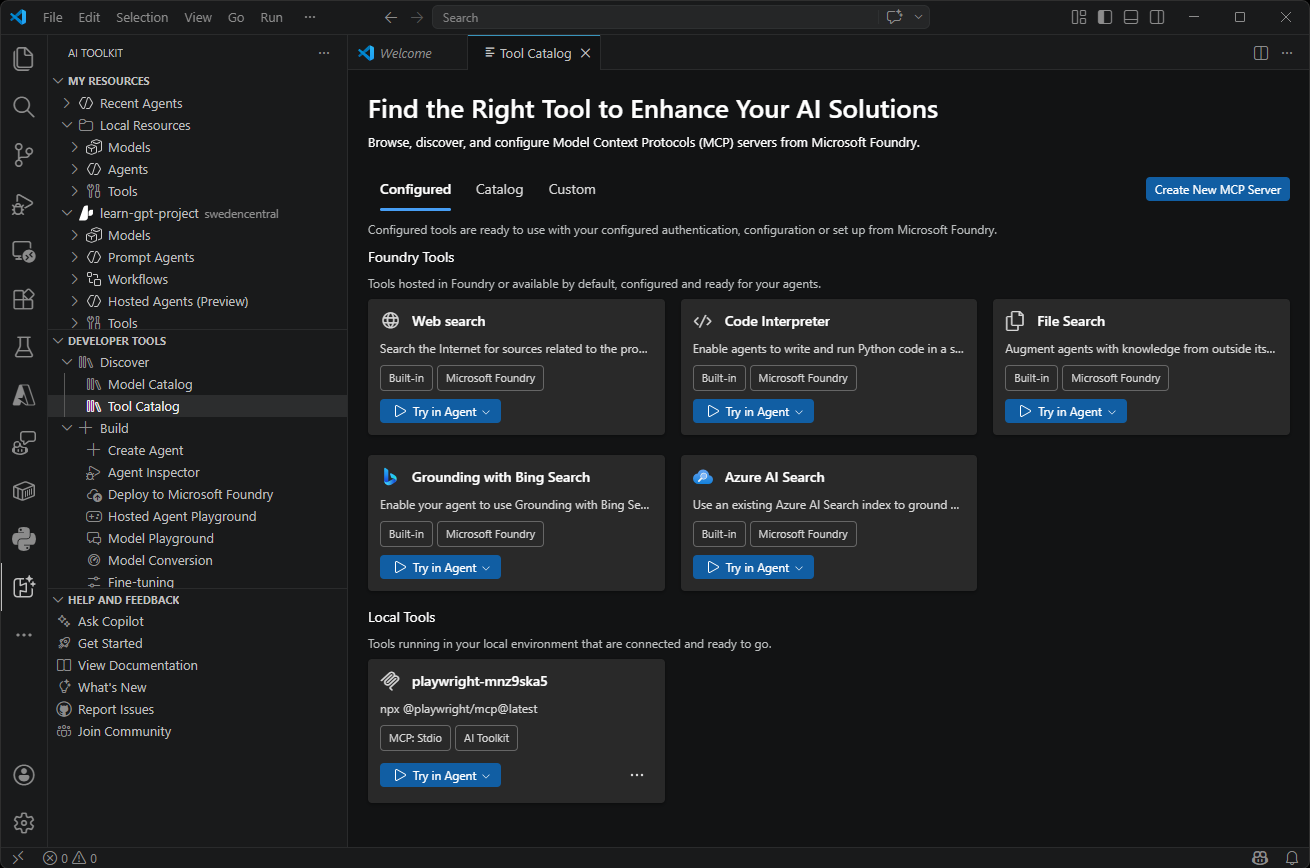 |
| Fine-tuning | Customize and adapt models for specific domains and requirements. Train models locally with GPU support or use Azure Container Apps for cloud-based fine-tuning. | 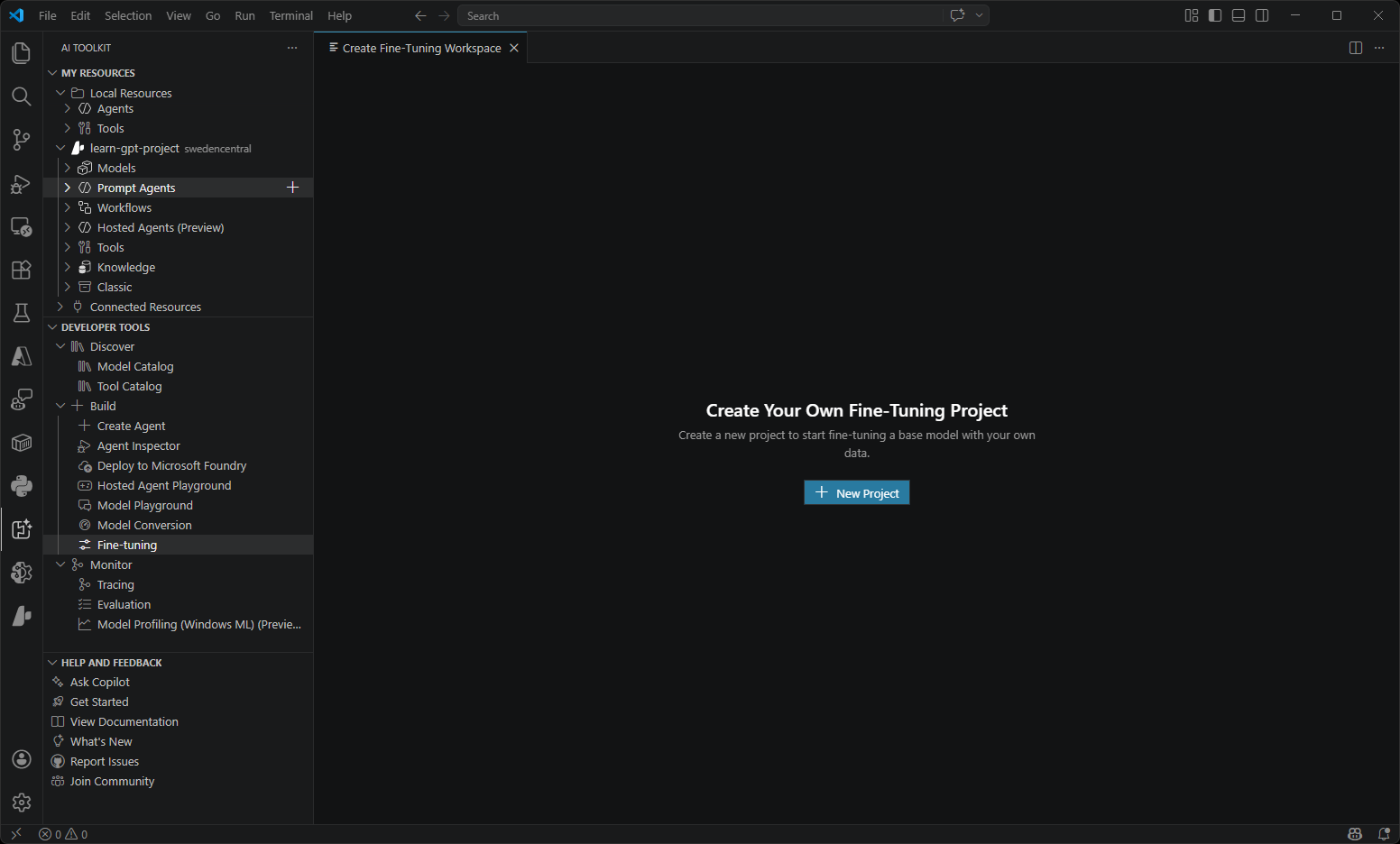 |
| Model Conversion | Convert, quantize, and optimize machine learning models for local deployment. Transform models from Hugging Face and other sources to run efficiently on Windows with CPU, GPU, or NPU acceleration. | 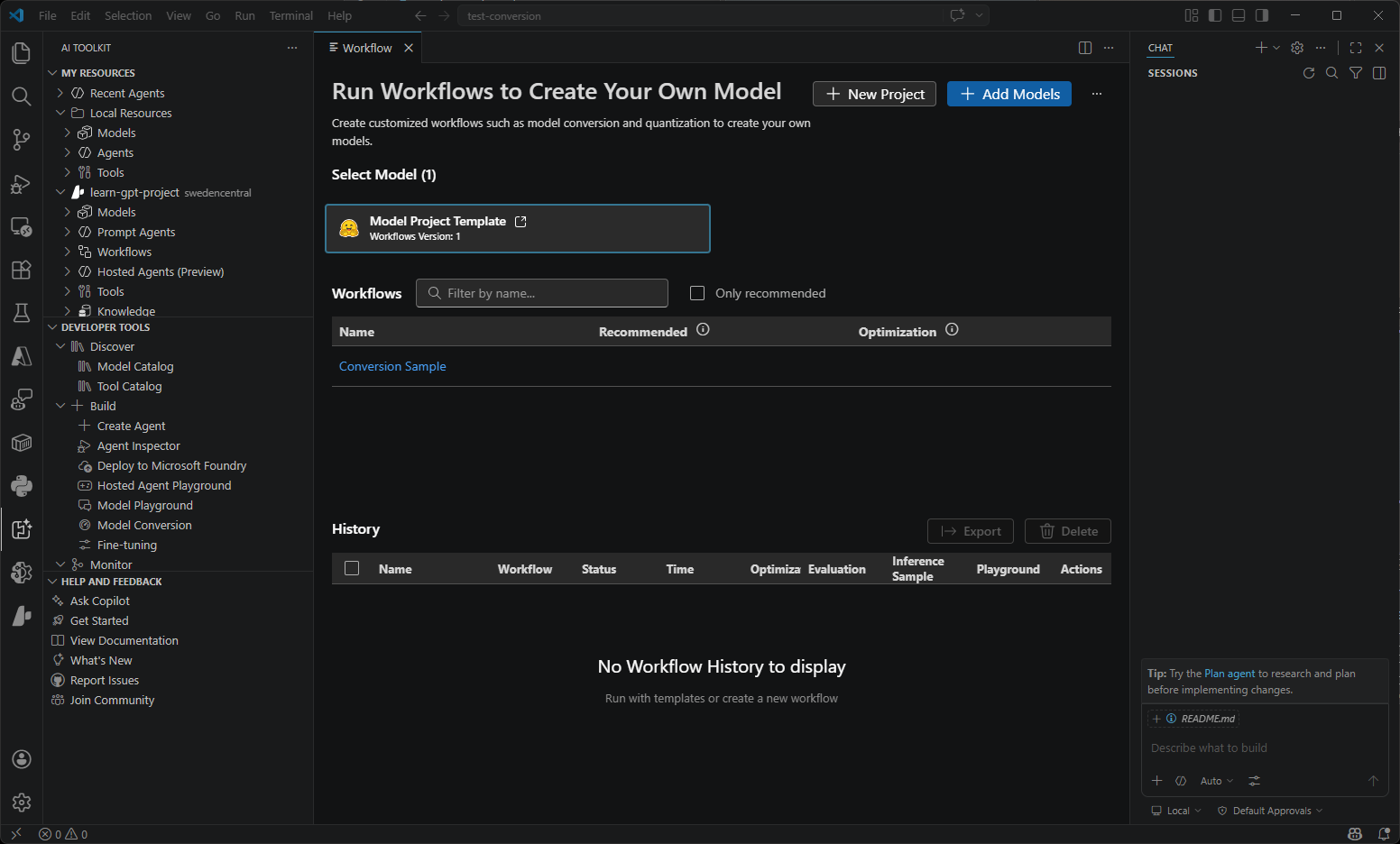 |
| Tracing | Monitor and analyze the performance of your AI applications. Collect and visualize trace data to gain insights into model behavior and performance. | 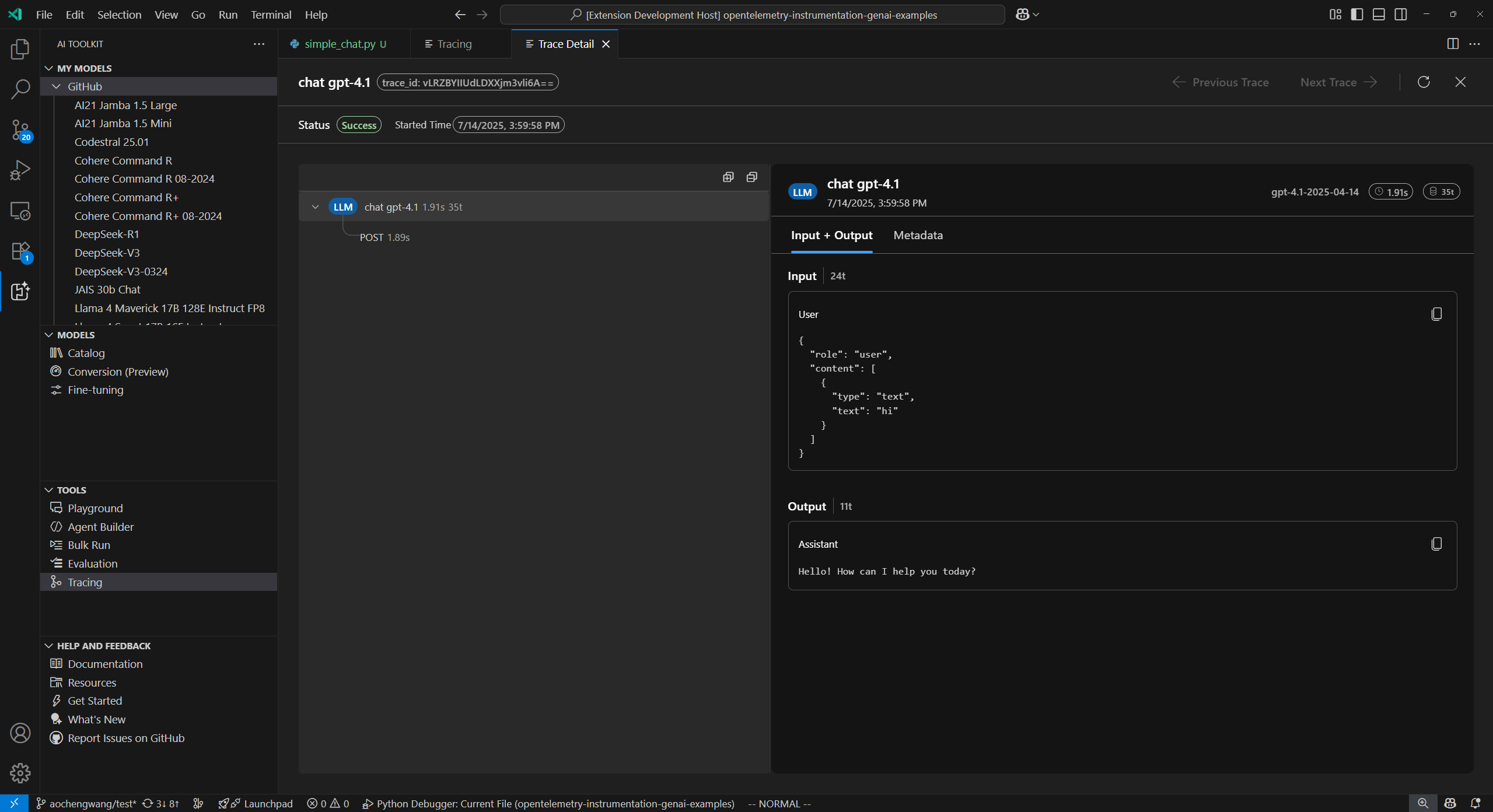 |
| Profiling (Windows ML) | Diagnose the CPU, GPU, NPU resource usages of the process, ONNX model on different execution providers, and Windows Machine Learning events. | 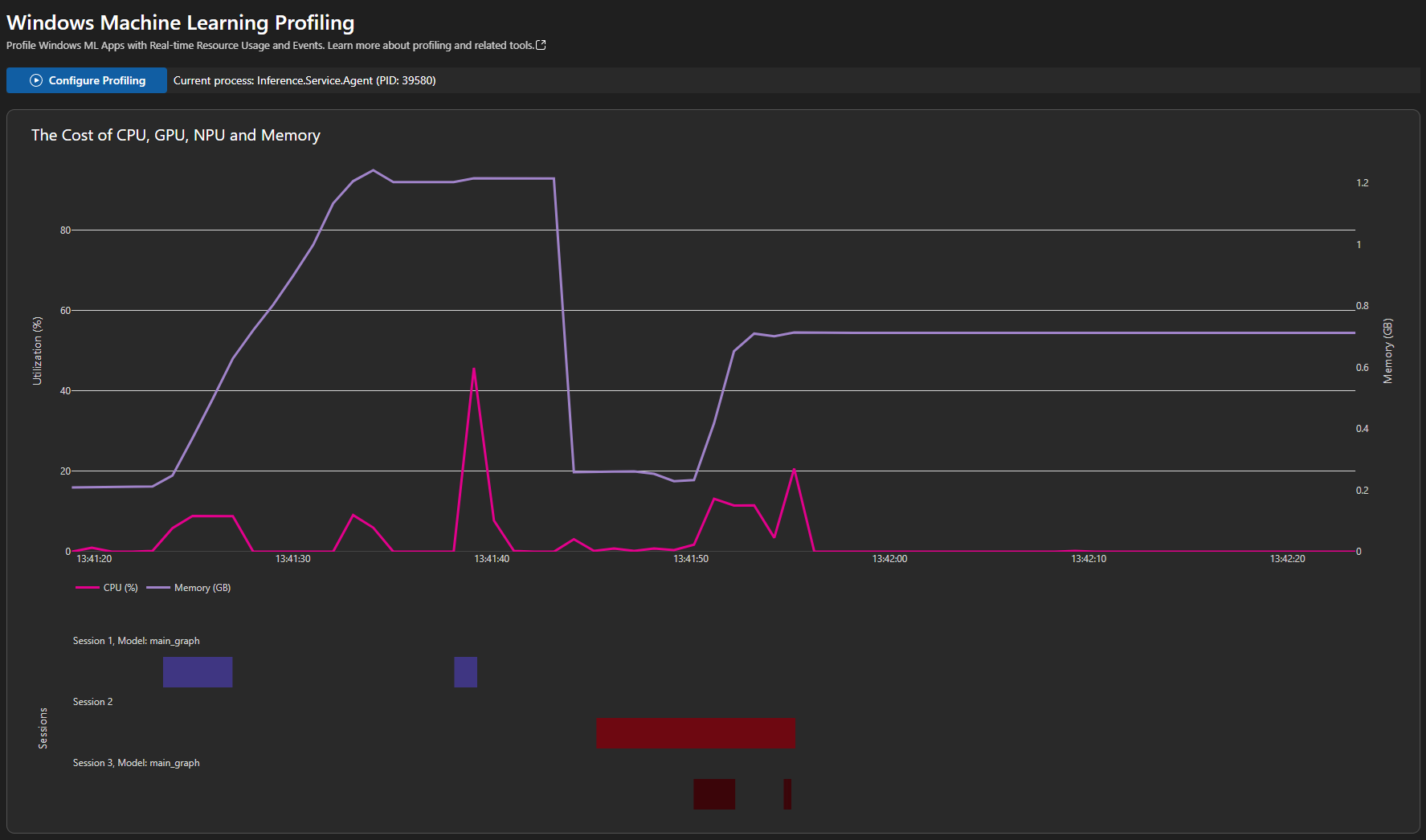 |
Who is Foundry Toolkit for?
Foundry Toolkit is designed for anyone working with generative AI, from beginners to experts:
Developers
- App developers building AI-powered applications who need to integrate language models
- Full-stack developers looking to add intelligent features to web and desktop applications
- Mobile developers prototyping AI functionality before production deployment
AI engineers & data scientists
- AI engineers fine-tuning models for specific domains and deploying to production
- Data scientists evaluating model performance and comparing different approaches
- ML engineers converting and optimizing models for efficient local deployment
Researchers and educators
- AI researchers experimenting with different models and prompt engineering techniques
- Educators teaching AI concepts and demonstrating model capabilities
- Students learning about generative AI and hands-on model interaction
Key use cases
- Explore and evaluate models from providers like Anthropic, OpenAI, and GitHub
- Run models locally using ONNX and Ollama for privacy and cost control
- Build and test agents with prompt generation and MCP tool integrations
- Convert and optimize models for deployment across different hardware configurations
Install and setup
Quick installation
The .NET Runtime should be installed as Foundry Toolkit depends on it
The fastest way to get started is by installing the extension through the Visual Studio Marketplace:
After successful installation, the Foundry Toolkit icon appears in the Activity Bar.
Manual installation
You can also install Foundry Toolkit extension manually from the Visual Studio Code Marketplace. Follow the steps detailed in Install an extension.
Alternatively, select the Extensions icon in the Activity Bar.
-
Search for Foundry Toolkit for Visual Studio Code and select Install from search results.

Check the What's New page after installation to see detailed features for each version.
- After successful installation, the Foundry Toolkit icon appears in the Activity Bar.
Verifying and Installing Foundry Toolkit Pre-Requisites (Local Models)
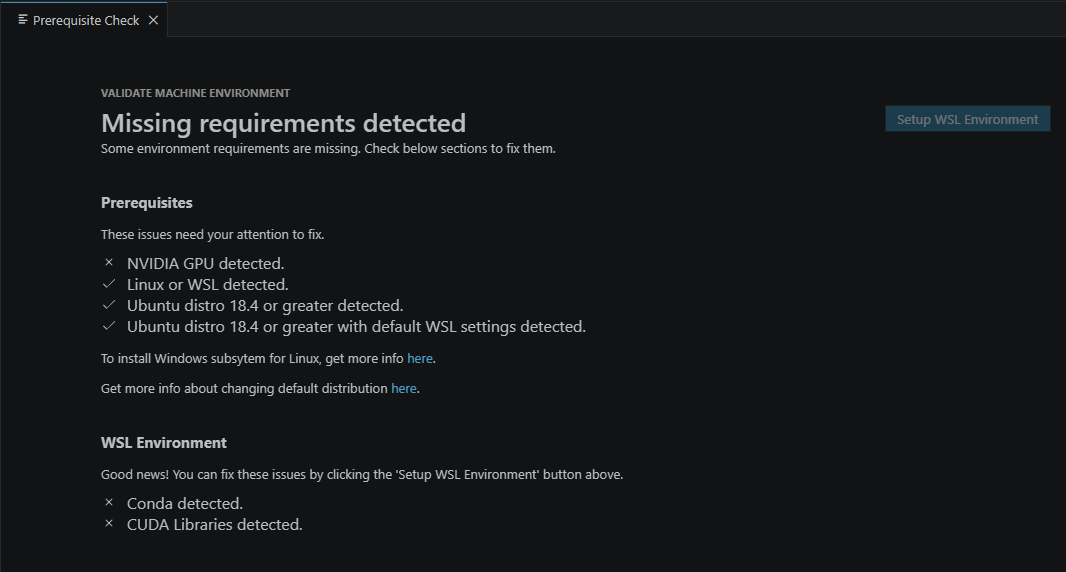
Foundry Toolkit provides local LLM running capabilities via Foundry Local, complete the Foundry local setup by running the Foundry Toolkit: Install environment prerequisites command to leverage these capabilities.
You can verify pre-requisites installation status with the Foundry Toolkit: Validate environment prerequisites Command:
Explore Foundry Toolkit
Foundry Toolkit includes the Foundry sidebar directly, so you manage your Microsoft Foundry resources and Foundry Toolkit features in one place.
The Foundry sidebar retires on June 1, 2026. All Foundry sidebar features are now available in the Foundry Toolkit sidebar.
Foundry Toolkit opens in its own view, with the Foundry Toolkit icon displayed on the VS Code Activity Bar. The extension has three main sections: My Resources, Developer Tools, and Help and Feedback.
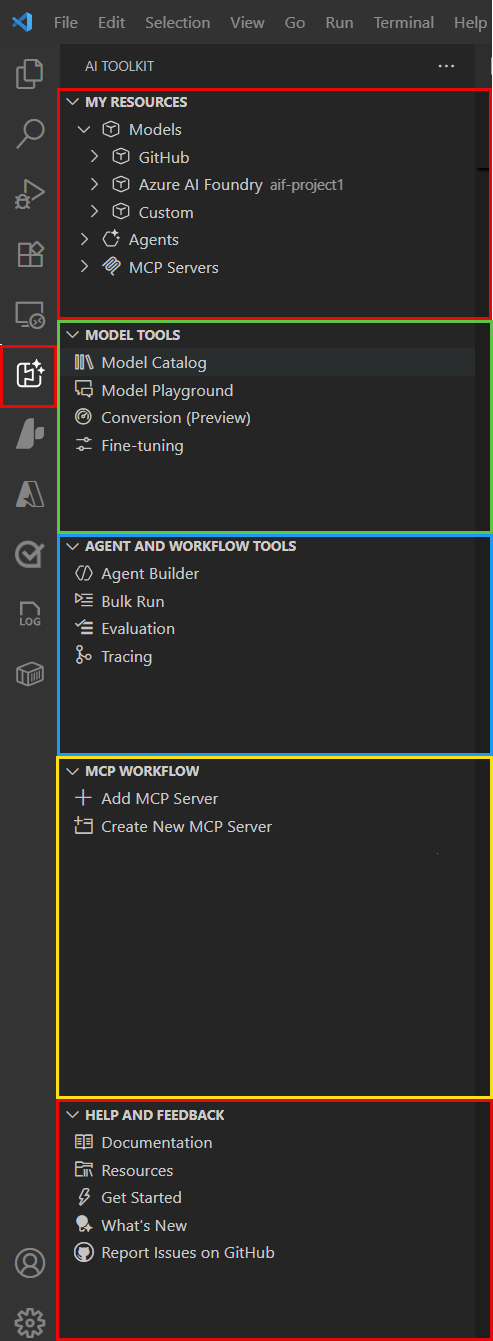
- My Resources: This section contains the resources you have access to in Foundry Toolkit. The My Resources section is the main view for interacting with your Azure AI resources. It contains the following subsections:
- Local Resources: This section contains the AI resources you have on your local machine, such as local models, agents, and tools.
- Your Foundry Project This section shows the Microsoft Foundry project connected to Foundry Toolkit. Use your Foundry project to manage and deploy AI resources, such as deployed models, prompt agents, hosted agents, connections, tools, vector stores, and classic agents.
- Models View models deployed in your project, including endpoint info like the target URI and authentication key.
- Prompt Agents View Prompt Agents (including previous versions) deployed in your project to test via the playground, view conversations, and set up evaluations.
- Workflows - View and create new declarative, predefined sequences of actions that orchestrate agents and business logic in a visual builder.
- Hosted Agents (Preview) - View Hosted Agents deployed in your project.
- Tools - Browse, discover, and configure Model Context Protocol (MCP) servers from Microsoft Foundry, or create a custom MCP server.
- Knowledge - View and add new vector stores and other data sources used by your agents.
- Classic - View agents and threads created in "classic" Foundry.
- Connected Resources: This section contains the resources that are connected to Foundry Toolkit from providers such as GitHub models.
- Developer Tools: This section contains the tools you can use to build and deploy your AI applications. The Developer Tools view is where you can find the tools available to deploy and then work with your deployed models and agents. It contains the following subsections:
- Discover: This section contains tools to help you discover and manage AI models and tools. It contains the following subsections:
- Model Catalog: The model catalog lets you discover and access AI models from multiple sources including GitHub, ONNX, Ollama, OpenAI, Anthropic, and Google. Compare models side-by-side and find the right model for your use case.
- Tool Catalog: Browse and manage the tools available in Foundry Toolkit.
- Discover: This section contains tools to help you discover and manage AI models and tools. It contains the following subsections:
- Build: This section is where you can find the tools available to deploy and then work with your deployed agents in Foundry Toolkit. It contains the following subsections:
- Create Agent: Create and deploy agents easily.
- Agent Inspector: Debug, visualize, and iterate on AI agents directly within VS Code.
- Deploy to Microsoft Foundry: Deploy your local agent to Microsoft Foundry as a hosted agent.
- Hosted Agent Playground: The hosted agent playground provides an interactive environment to experiment with your hosted agents.
- Model Playground: The model playground provides an interactive environment to experiment with generative AI models.
- Model Conversion: The model conversion tool helps you convert, quantize, optimize, and evaluate the prebuilt machine learning models on your local Windows platform.
- Fine-tuning: This tool allows you to use your custom dataset to run fine-tuning jobs on a pre-trained model in a local computing environment with GPU or in the cloud (Azure Container Apps) with GPU.
- Monitor: This section is where you monitor and analyze the performance of your AI applications. It contains the following subsections:
- Tracing: Trace capabilities to help you monitor and analyze the performance of your AI applications.
- Evaluation: Evaluate models, prompts, and agents by comparing their outputs to ground truth data and computing evaluation metrics.
- Model Profiling (Windows ML)(Preview): This tool allows you to diagnose the CPU, GPU, NPU resource usages of the process, ONNX model on different execution providers, and Windows Machine Learning events.
- Help and Feedback: This section contains links to the Foundry Toolkit documentation, feedback, support, and the Microsoft Privacy Statement. It contains the following subsections:
- View Documentation: The link to the Foundry Toolkit documentation.
- What's New: The link to the Foundry Toolkit release notes.
- Report Issues: The link to the Foundry Toolkit GitHub repository issues page.
- Join Community: Join the Foundry Toolkit community to share feedback and connect with other users and the Foundry Toolkit team.
Next steps
- Get more information about adding generative AI models in Foundry Toolkit
- Use the model playground to interact with models
- Develop agents with the Agent Builder and debug them with the Agent Inspector